[Qgis] 유동인구, 생활인구 데이터 가공, 시각화 하기 | 구글 코랩으로 csv데이터 가공 | 하는 법 | 서울 열린데이터 광장 활용
1. 가공할 수 있는 적절한 데이터 찾기
서울시에서 제공하는 유동인구 데이터를 찾아보자
https://data.seoul.go.kr/dataList/OA-21704/F/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
서울 열린데이터 광장의 '서울시 년도별 유동인구 기본정보(2009, 2012~2019)'는 최신 데이터가 2015에 멈춰있다.
https://data.seoul.go.kr/dataList/OA-15964/S/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
위 데이터가 가장 명확해보이나, 위치정보를 확인해보았을 때, 길음생활권을 포함하는 성북구 데이터가 존재하지 않는다.
데이터를 찾느라 애먹는 와중에 아래와같이 서울시 상권분석 서비스에서는 서울 전역, 심지어 길거리에서 모든 유동인구가 제공되는 것을 보았다.

서울시 상권분석 서비스에서 어떠한 데이터를 이용하여 보여주는지 확인한 결과 '서울시 생활인구' 데이터를 가공하는 것을 알 수 있었다. 어느정도의 정확도를 가지고있는지, 생활데이터를 길단위, 건물단위 유동인구로 정보로 변환하는 방식은 알 수 없으나 시간대별, 성별과 나이대로 나눠진 세부 인구 데이터를 이용하는 것을 알았다.

서울시 생활인구 데이터란?
서울시와 KT가 공공빅데이터와 통신데이터를 이용하여 추계한 서울의 특정지역, 특정시점에 존재하는 모든 인구
라고 한다.
생활인구 데이터는 이곳에서 찾을 수 있다.
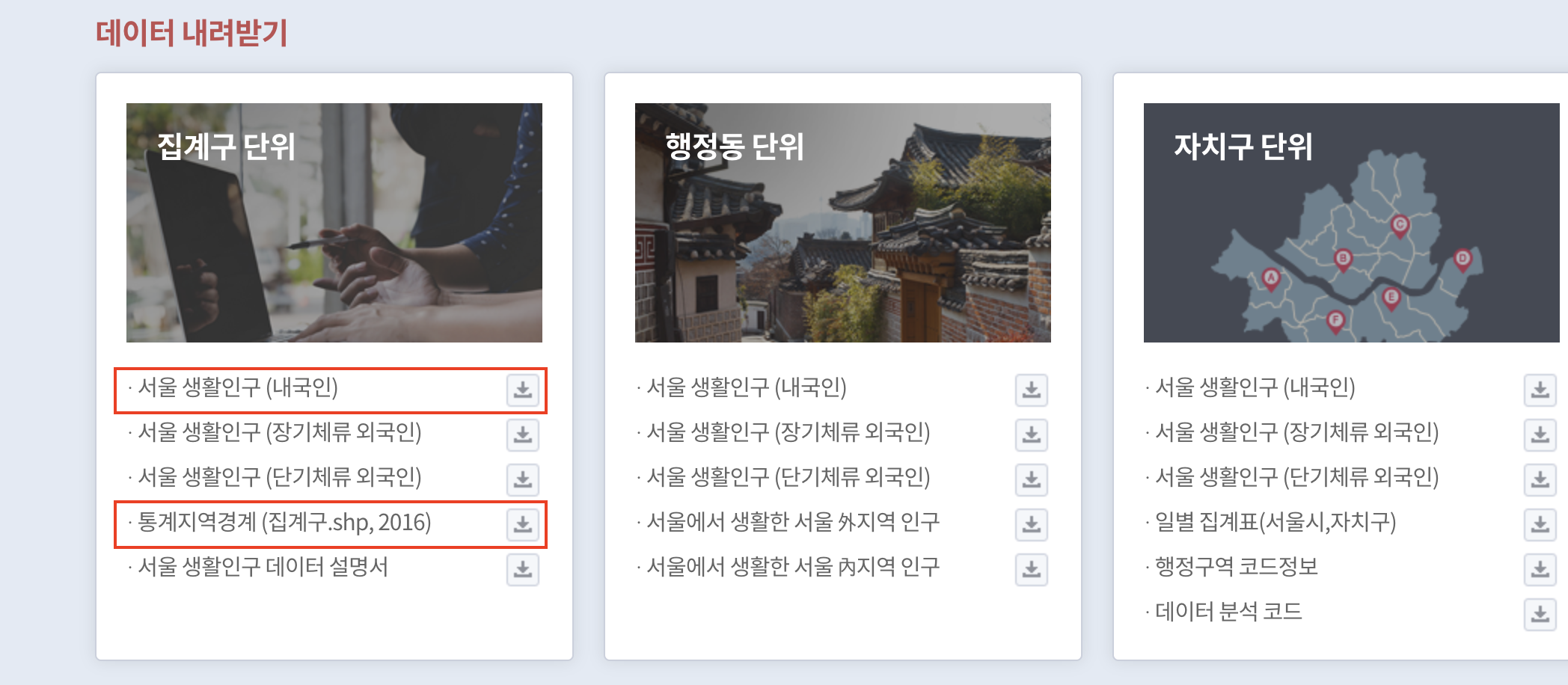
집계구단위의 생활인구(내국인)과 qgis를 이용할거니 shp파일을 다운받았다. 참고로 shp 좌표계는 EPSG 코드 5179로 검색해서 맞춰야한다.
2. 구글 코랩을 이용한 데이터 가공

최신순으로 위에 두 파일은 이상하게 안에 데이터 없다.. 알맹이 있는 데이터를 열어보면 약 125mb짜리 csv파일이 있다.
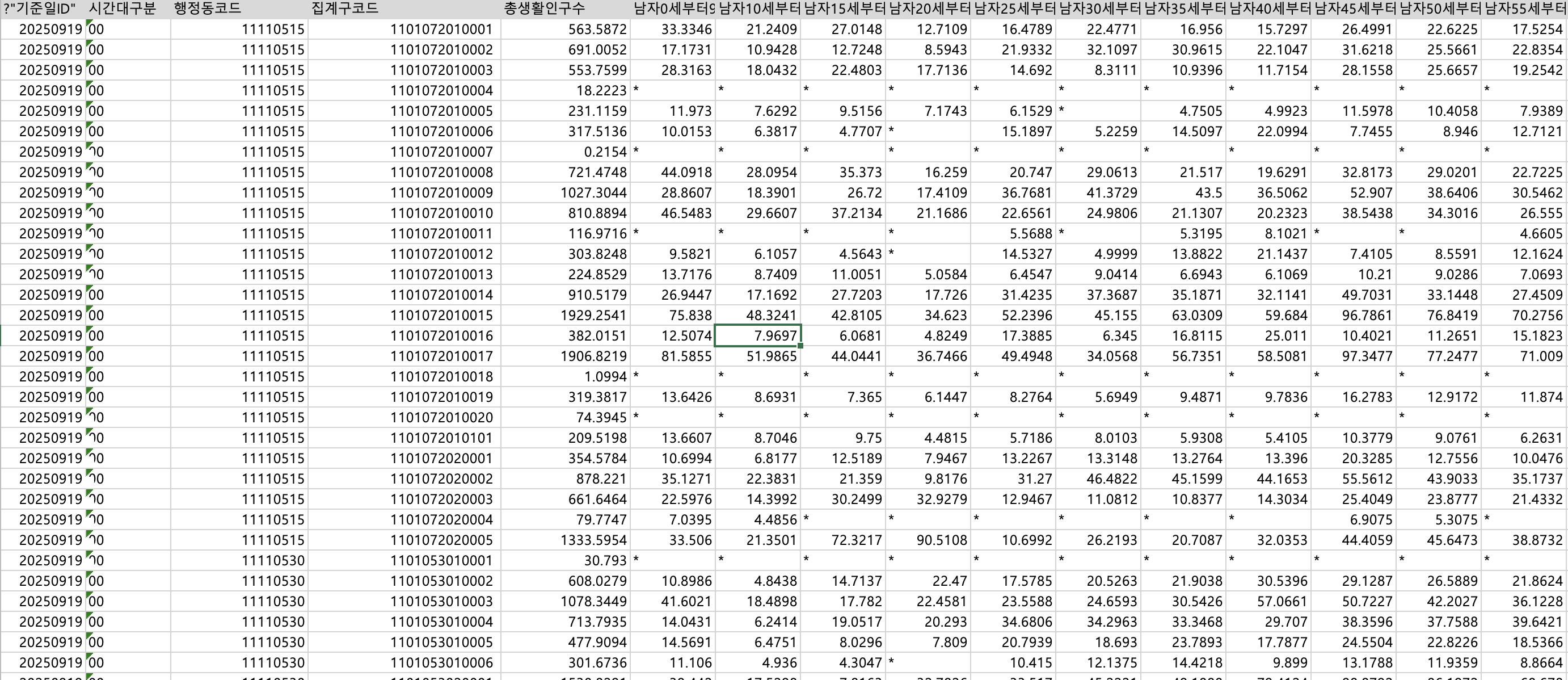
데이터를 살펴보면
기준일, 시간대구분, 행정코드, 집계구코드, 총생활 인구수, 성별/연령대별 인구수가 나온다.
raw data로 알 수있는 내용
2025년 9월 19일에 기록된 데이터이고
하나의 행정동 코드에 여러개의 집계구 코드가 있으며
그 하나의 집계구 코드에 0시부터 23시까지의 각 시간별 24개 데이터가 존재함
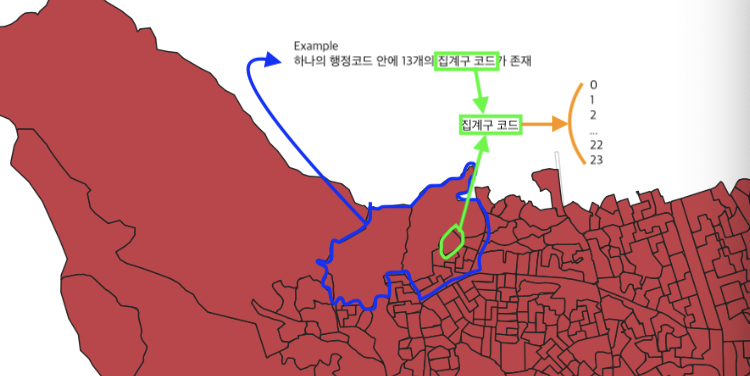
시간대별, 집계구별 다 흩어져있는데 사용하고자하는 데이터만 추출하고 최적화해보도록 하겠다.
위 shp파일을 qgis에서 열고 길음 생활권을 포함한 근처 바운더리만 선택하여 새로운 shp파일로 저장한다. 그러면 사용하고자하는 지역의 shp파일만 남고 이를 csv로 다운받아 해당하는 집계구 코드를 참조하는 데이터로 이용할 것이다.
데이터를 가공하는 알고리즘은 다음과 같다.
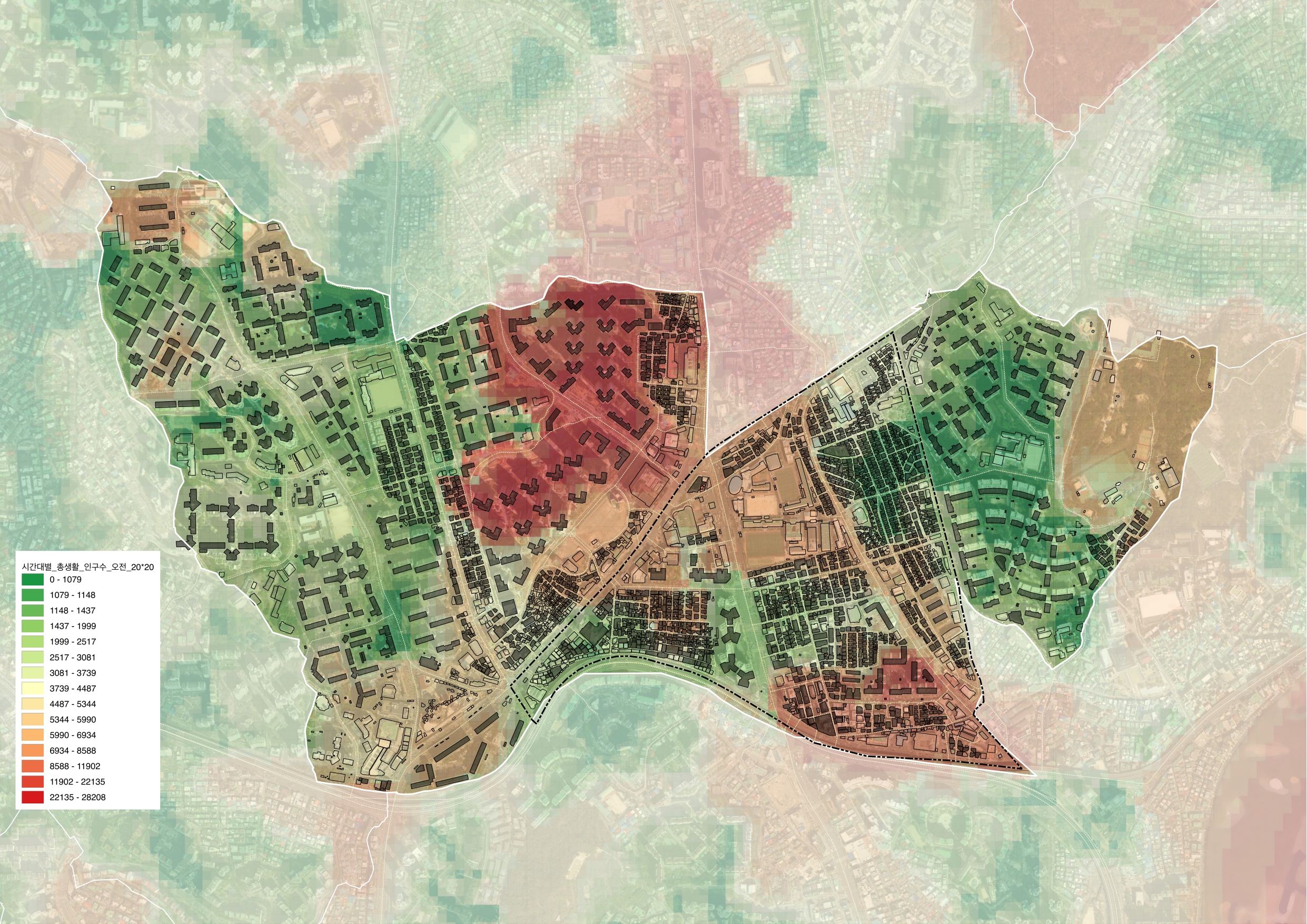
최종적으로 얻고자 하는 최적화된 데이터는 시간대별 유동인구 정보로, 예를들어 오전(6시부터 11시까지)시간대에 해당하는 데이터들만 모여있는 csv파일이다.
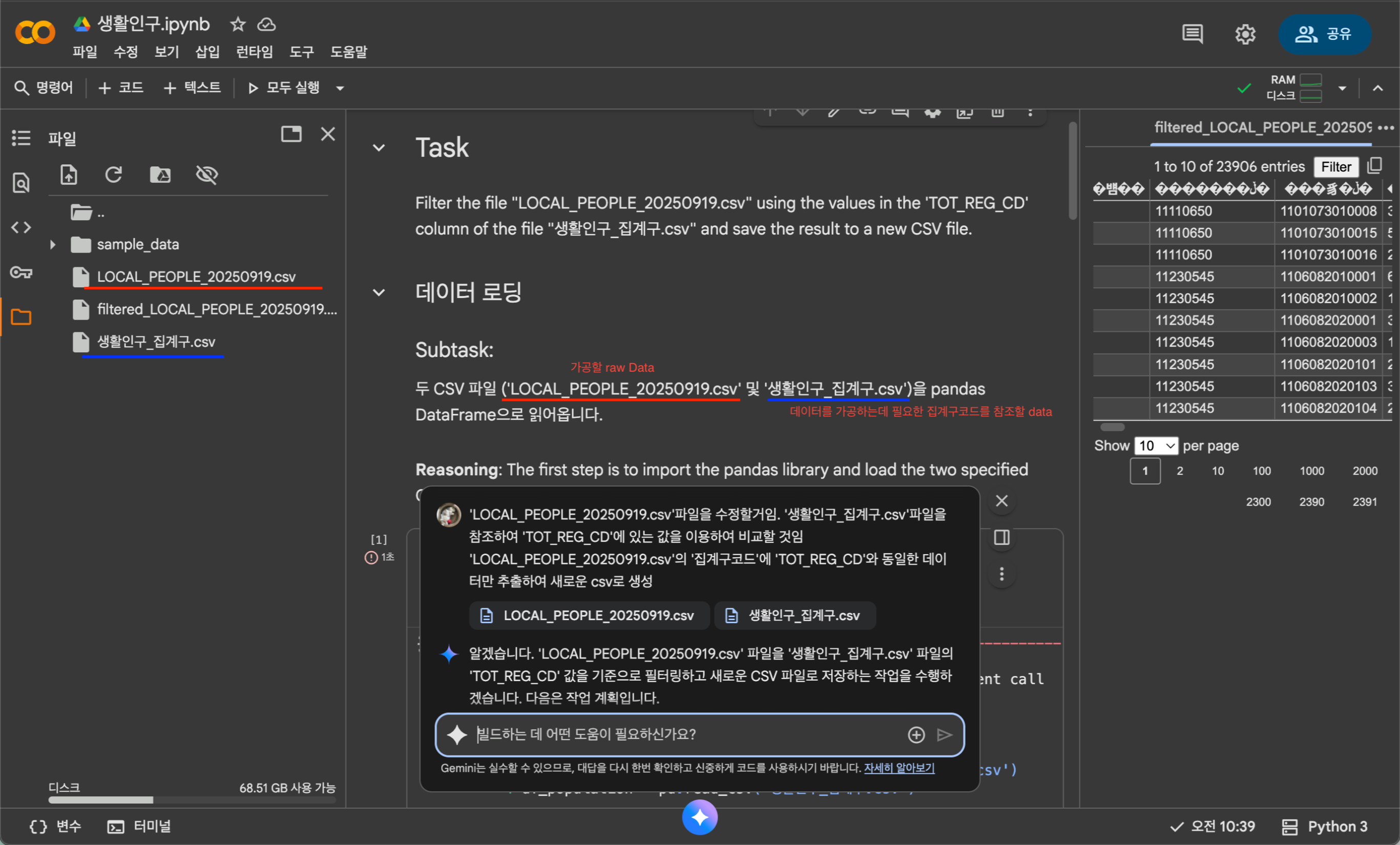
1. 이 shp파일의 집계구를 이용하여 위 csv데이터의 집계구코드 와 동일한 부분을 추출하여 새로운 'filtered_.csv'파일로 제작
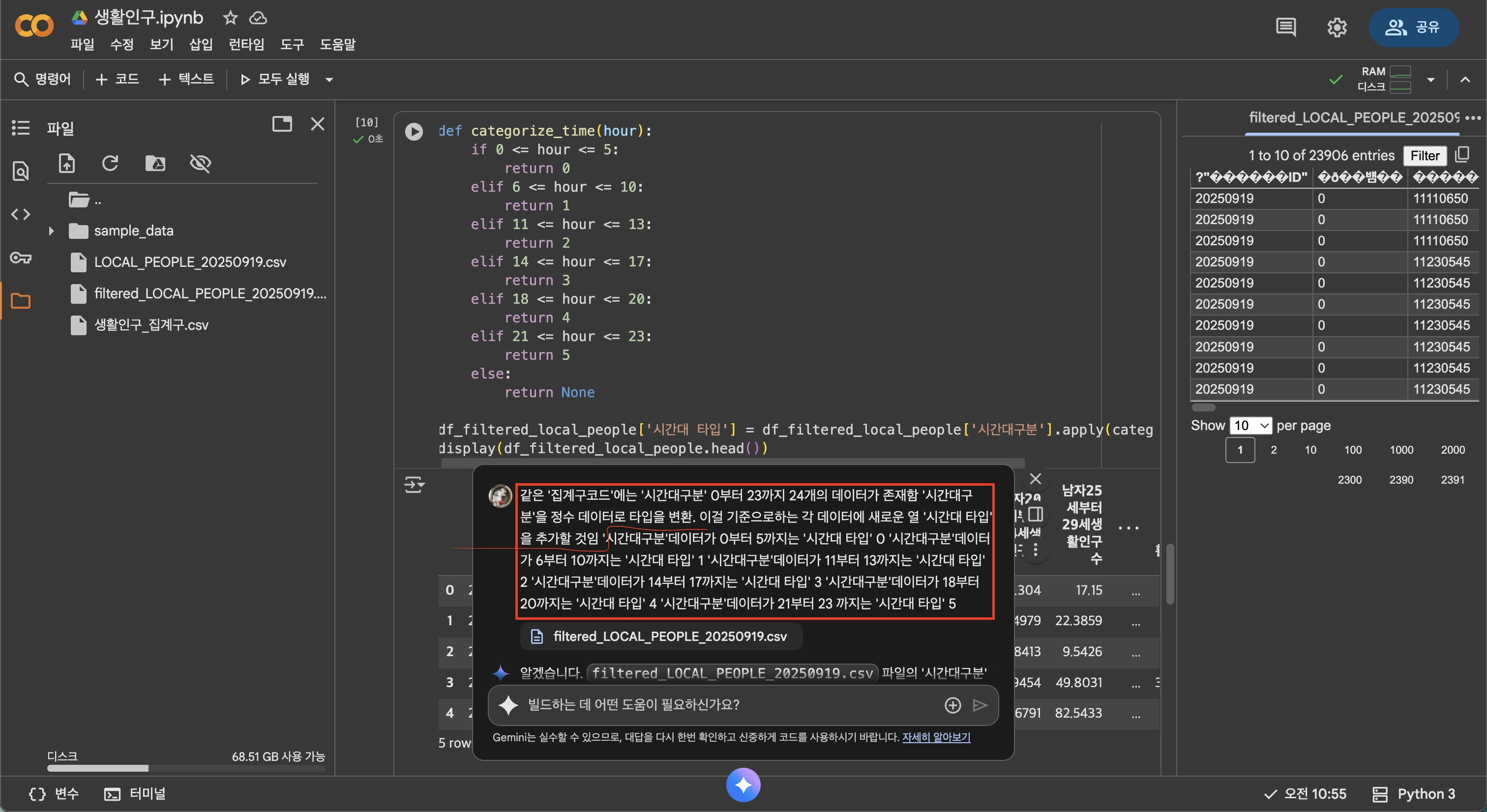
2. 'filtered_.csv'에서 0부터 23까지 나눠져있는 시간대열을 이용하여 범위(새벽 0 : 0시~6시 / 오전 1 : 6시~11시 / 점심 2 : 11시~14시 / 오후 3 : 14시~18시 / 저녁 4 : 18시~21시 / 밤 5 : 21시~24시)에 맞게 분류하여 '시간대_타입'의 열을 생성.
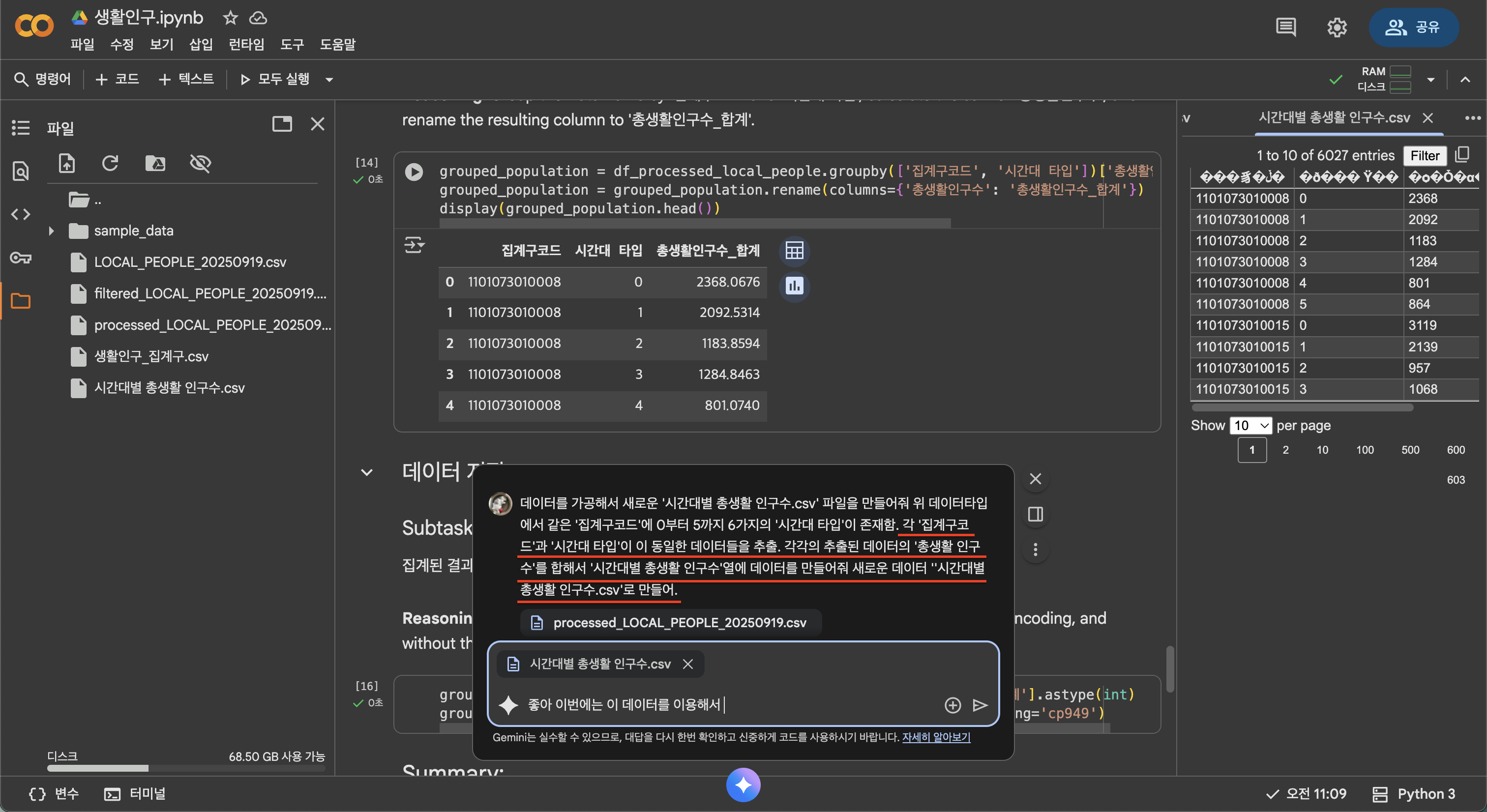
3. 데이터에서 '집계구','시간대_타입'가 동일하다면 '총 생활인구 수'를 합함.
4. 각 시간대별 유동인구 정보를 알고싶으니 '시간대_타입'별로 그룹화. 그룹화된 하여 각 6개의 csv파일을 추출.
음 다시보니간 3,4번 순서를 바꾸는게 더 논리적이었을 것 같다..
데이터를 가공하는 방법은 phython을 이용하는 AI 혹은 직접 코딩, r프로그램을 이용할 수 있다.
코드를 오류없이 빠르게 써주고 각 단계별로 코드를 확인할 수 있는 phython 구글 코랩 + 구글AI (gemini) 을 이용하였다.
본인과 같이 직접 코딩하기에는 시간이 오래걸리지만 코드를 빠르게 읽을 수 있는 사람은 구글 코랩 + 구글AI (gemini)을 추천한다. 챗지피티는 결과물 우선이라 어떤 흐름으로 코드가 써지고 작동하는지 바로 알기가 어려워 답답하다. 말도 안듣고...
1. shp파일의 집계구를 이용하여 위 csv데이터의 집계구코드 와 동일한 부분을 추출하여 새로운 'filtered_.csv'파일로 제작한 모습
2. 'filtered_.csv'에서 0부터 23까지 나눠져있는 시간대열을 이용하여 범위(새벽 0 : 0시~6시 / 오전 1 : 6시~11시 / 점심 2 : 11시~14시 / 오후 3 : 14시~18시 / 저녁 4 : 18시~21시 / 밤 5 : 21시~24시)에 맞게 분류하여 '시간대_타입'의 열을 생성. 을 시행하는 모습
3. 데이터에서 '집계구','시간대_타입'가 동일하다면 '총 생활인구 수'를 합함.
4. 각 시간대별 유동인구 정보를 알고싶으니 '시간대_타입'별로 그룹화. 그룹화된 하여 각 6개의 csv파일을 추출.
그리하여 총 6개 타입의 시간대별 집계구에 따른 유동인구 데이터를 얻게되었다.
3. 데이터 시각화
20m*20m 그리드 격자를 생성하여 단위면적당 유동인구의 경향을 시각화해보겠다.
단위면적당 데이터 산출 방식은 아래 글을 참고.
https://binggamel.tistory.com/290
[Qgis] TIN보강, 단위면적당 데이터 산출 넣기
TIN 보간이란?TIN(Triangulated Irregular Network) 보간은 불규칙적으로 분포된 점 데이터를 이용하여 연속적인 지형 표면을 생성하는 기법입니다. TIN 보간은 점 데이터의 공간적 분포와 특성을 잘 반영할
binggamel.tistory.com




최종 산출물
https://binggamel.tistory.com/295
[QGIS] 유동인구, 생활인구 시각화 / 길음 생활권
시간대는 임의로 데이터를 분류하여 이용함 새벽 : 0시~6시오전 : 6시~11시점심 : 11시~14시오후 : 14시~18시저녁 : 18시~21시밤 : 21시~24시
binggamel.tistory.com
'건축과 산업디자인 > 건축' 카테고리의 다른 글
| [Nano Banana] 도시설계 렌더링에 AI 활용 / 프롬프트 (0) | 2025.11.03 |
|---|---|
| 수치지형도, 컨투어 라인으로 대지 모델링 그래스호퍼 (0) | 2025.09.28 |
| [Qgis] 유동인구, 생활인구 시각화 / 길음 생활권 (0) | 2025.09.26 |
| [Qgis] 격자구역으로 연면적 통계 산출 (0) | 2025.09.11 |
| [Qgis] 가구총괄, 인구밀도, 주택 거처 수 분석 (0) | 2025.09.11 |



